
「Evidence使ってみた」をEvidenceで書いてみた
EvidenceというBIツールの紹介をせっかくなのでEvidenceで書いてみました。
TableauやPower BIといった皆さんが想像するBIツールとは少し毛色が異なります。
開発・運用する側に大きなメリットがあるツールだと思うので、是非試してみてください。
前提事項
本ページで扱う内容
- Evidenceの簡単な紹介
- Evidenceがどのようなツールで、どんな特徴を持つかを簡単に紹介
- 簡単なハンズオン
- Evidenceをセットアップして、データを接続し、グラフを作成する基本的な操作方法を解説
本ページで扱わない内容
- 他BIツールとの詳細な比較
- TableauやPower BIなど、他のBIツールとの具体的な機能比較については触れていません
- デプロイ周り
- Evidenceプロジェクトの本番環境へのデプロイ方法は述べていません
コードで管理できるBIツール
EvidenceとはmarkdownとSQLを用いてデータ製品を構築するオープンソースフレームワークです。
MITライセンスで公開されているため、商用利用も可能です。 Evidenceは、以下の特徴があります。
素晴らしいUXの提供
- デバイスを問わずに読める
- このページもスマホでも違和感なく読めると思います(特に設定はしていません)。
- 高速なページ読み込み
- デバイスを問わずに読める
容易な構築・デプロイ・管理
- SQL、markdown、豊富なコンポーネントによるシンプルな記述
- gitによるバージョン管理

日本語の記事も何本か上がっているので、詳しく知りたい方は以下の記事を参考にすると良いと思います。
またEvidenceの公式サイトからExapmlesとしていくつかBIレポートの例が挙げられているので、そちらも見ると良いかもしれません。
個人的にここが良い
(人によっては)学習コストが少ない
業務でmarkdownやSQLを書いている人にとっては、ほぼ学習コストなしで使えることができます。分からないことがあればネットで調べれば出てくるし、ChatGPTに聞いてもこの2つは割と正確に答えてくる印象です。
他のBIツールではGUIでの操作がメインになると思います。これは、サクッと作成する分には簡単に操作できる明確なメリットがあります。 一方で、どのように操作をしたらそのグラフができるのか言語化しずらい面があると思います。 どこを変えたのか分からなかったり、どうやってそのグラフが作られているのか分からなかったり…
Evidenceはドキュメントが整っており、使えるコンポーネントやオプション値はドキュメントに記載されています。
Gitでバージョン管理出来る
Gitで管理できます。 Evidenceでは、markdownファイルに文章やグラフの情報を書いていきます。テキストファイルに過ぎないので、Git上で変更点の差分を容易に確認することができます。 また複数人での開発や、本番用と検証用を分ける際にもブランチを切り分けるなどして、並行して開発することができます。
実際に使ってみる
導入してみる
最も簡単な方法は、VSCodeの拡張機能を使用することです。
インストールしたらコマンドパレット(Ctrl/Cmd + Shift + P)を開いて、Evidence: New Evidence Projectを入力します。
フォルダの確認が入ると思うので、OKを押すとEvidenceのプロジェクトが作成されると思います。
Evidence serverを起動してみる
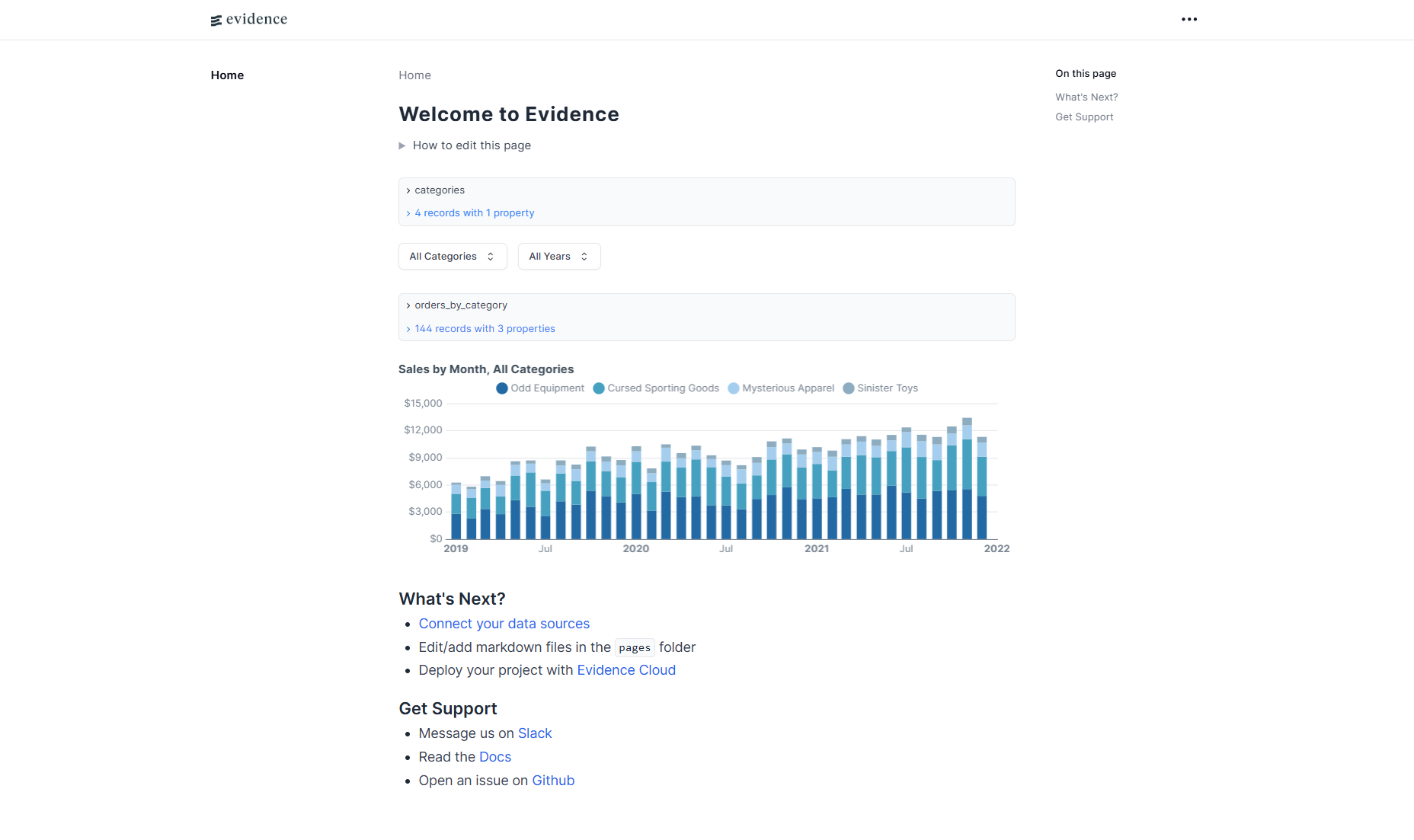
次にローカルでEvidence serverを起動してみます。 VSCodeの画面下部に「Start Evidence」があると思うので、それをクリックすると起動します。 (もしない場合には、VSCodeを再起動すると表示されるようになると思います)

起動に成功すると、ブラウザ上に下の画像のように表示されると思います。 上手くいかない方は、Node.jsかNPMが入っていない可能性が高いです。
データを接続してみる
サーバの起動に成功したら、データを接続してみます。 Evidenceでは様々なデータソースに対応しています。 このページではローカルに保存されているCSVファイルを接続してみます。
※これからの説明には、下の「使用データ」を用います。ダウンロードできるようになっているので、必要に応じてダウンロードしてください。データ整形とか特にしてないので汚いです。
Evidence上の右上にある三点リーダーから「Settings」のページに飛びます。 そこから以下の通りに進めてください。
- 「Data Sources」の「Add new source」をクリック
- 「Datasource Type」はcsvを選択、「Source name」は適当な名前を入力し「Confirm」をクリック
- 「Confirm Changes」をクリック
- VSCode上で
sources/testが作成されていることを確認 - CSVファイルをそのファルダに追加
- Evidence serverを再起動
三点リーダーの「Schema Viewer」に追加したCSVファイルの情報が載っていれば成功です。
グラフを描いてみる
実際にグラフを描いてみます。基本的にはpages/のmarkdownファイルに書いていくことで、作成することができます。
Evidence の魅力の一つに、Business Intelligence as Code と公式が謳っているように、BI ツールをコードで管理することができます。
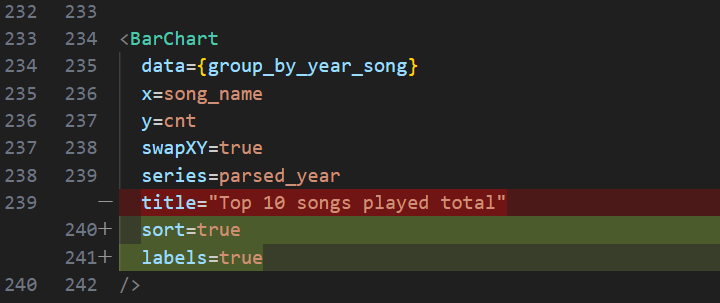
例えば、index.mdに以下のように書くとこんなグラフを表示させることができます。
```sql group_by_song
--- 楽曲ごとの演奏数を算出し、上位10件を抽出
select
song_name,
count(*) as cnt
from test.babymetal_setlists --- csvの場合は, your_csv_source_name.csv_file_name
group by song_name
order by cnt desc
limit 10
```
<BarChart data={group_by_song} x=song_name y=cnt swapXY=true />さらにクエリ文を変更したり、BarchartのOptionsを追加したりすることで、グラフを色々変更できます。
このようにオプションを指定してしながらグラフを作成していくのは、Python の Matplotlib や MATLAB の plot に近しいものがあるので、親近感が沸く方も多いと思います。
またグラフだけでなく、値のみの表示や文中にクエリの結果を仕込むこともできます。
最も演奏された楽曲
(年を変更すると、下の文が変化すると思います。)
2024年に最も歌われた楽曲は、 METALI!!で 38回です。
このようにして、EvidenceはSQLやMarkdownでグラフやテーブルを記述できます。 他にも色々なコンポーネントがあるので、試してみると面白いかもしれません。
最後に
Evidenceの紹介と簡単なハンズオンっぽく書いてみました。デプロイ周りの話も書きたかったのですが、データの取り扱いとGitへ不慣れな方もいるとおもうので割愛しました。
BIツールをコードで管理できる点は、データサイエンティストやデータエンジニア、BIツールに慣れていないエンジニアにとって大きなアドバンテージになると思います。 特に業務でMarkdownやSQLを使っている方にはすぐに馴染むはずです。
まだまだ認知度が低いツールですが、IssueやDiscussionもGithubやSlack上で盛んに行われており、これからのアップデートにも期待できます。